SiliconValleyGirl LLM: How I Built a RAG from 34 YouTube Transcripts
In short — this is the story of how a manual batch of transcripts turned into a narrow local bot for the Silicon Valley Girl interviews: with search across the last six months of videos, precise YouTube timecodes, short answers, and honest refusals when there is no confirmation in the corpus.
An important detail at the very beginning: I initially tried to automate transcription through Codex. It refused to do it, citing copyright issues. So I didn’t argue with the policies and simply manually processed all the videos through the Glasp YouTube Summary extension. That’s how a database of 34 transcripts appeared, and on top of it, I could safely build the RAG.
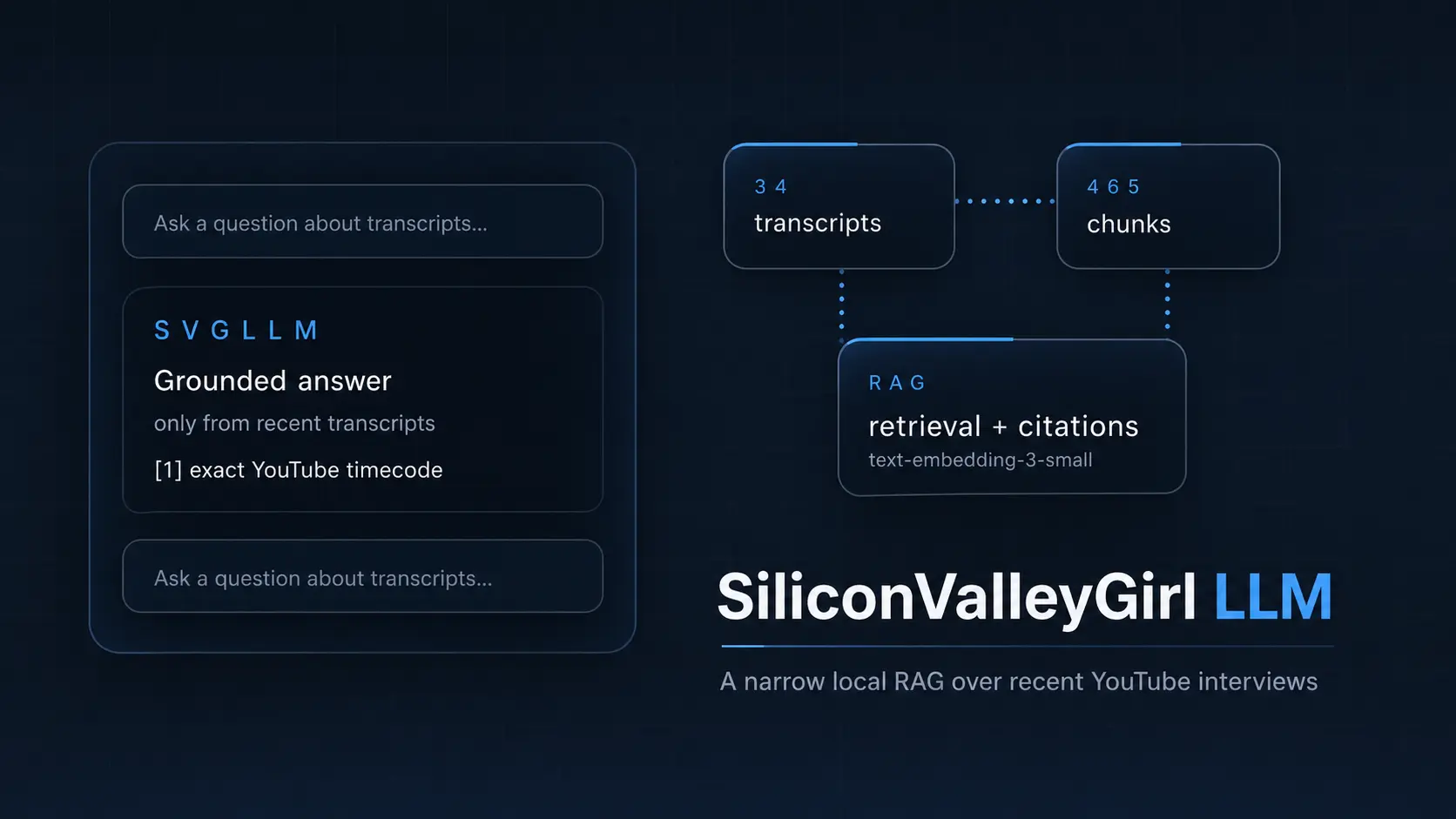
Why Build a Separate Bot at All
I didn’t need another universal chat. There already are universal chats: ChatGPT, Claude, Perplexity, and dozens more. I needed a small tool with a strict contract: to answer only about recent Silicon Valley Girl interviews and show exactly where the idea came from.
In practice, this is a completely different UX. When the bot says “OpusClip turns long videos into short clips,” it’s important not only the sentence itself but also the link to the exact video fragment. If it answers about Higgsfield, the sources must be about Higgsfield, not some random piece about startups. If there is no confirmation — better an honest refusal than a confident hallucination.
Manual Corpus Preparation
The first layer of the project was as unromantic as possible: gather raw material. After Codex refused, I opened the videos on the channel, ran them through Glasp, saved the text, and brought everything to a single format.
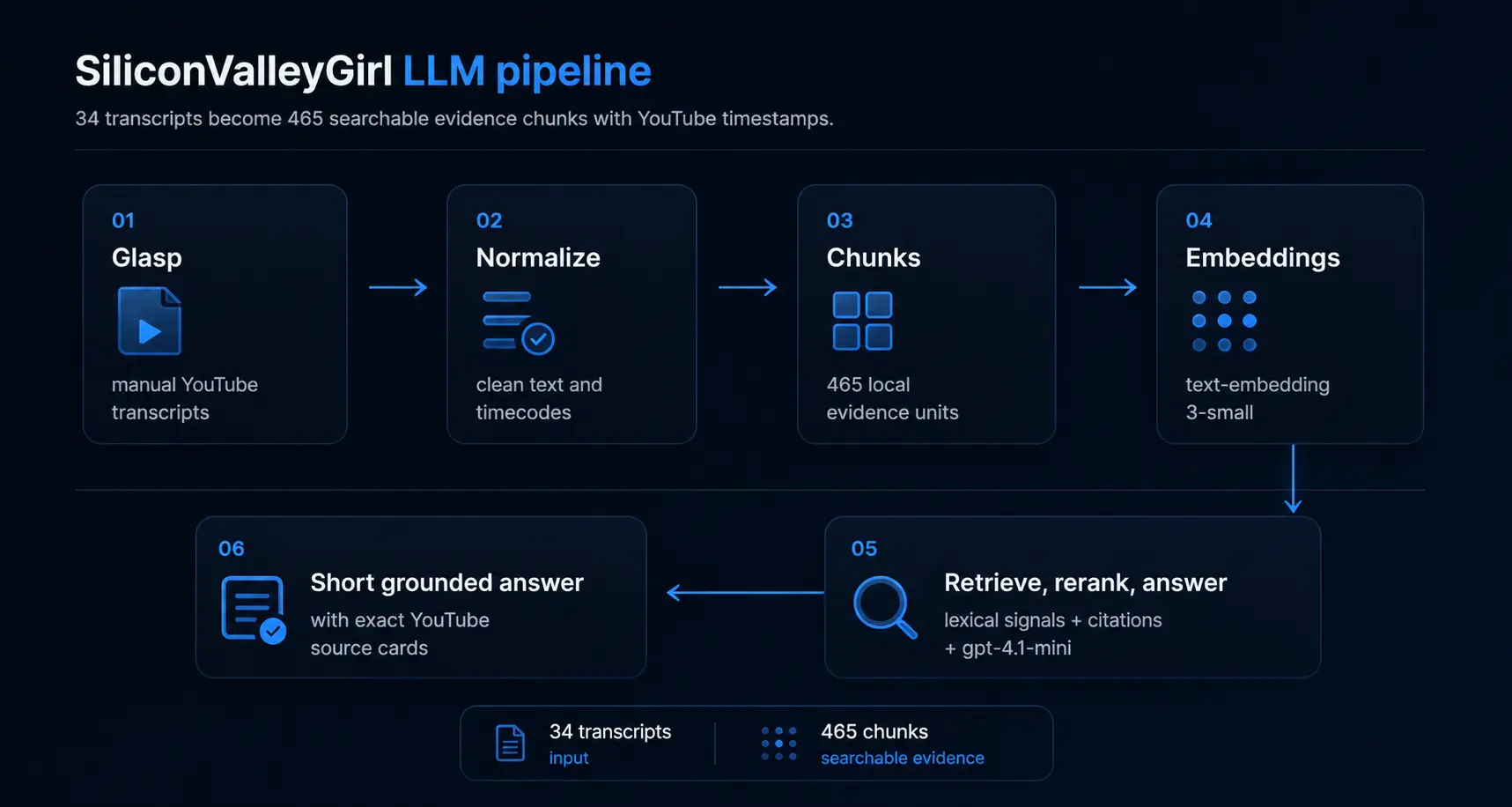
As a result, a small but manageable corpus was created:
| Parameter | Value |
|---|---|
| Videos | 34 |
| Publication Range | October 30, 2025 - April 23, 2026 |
| Chunks after normalization | 465 |
| Embedding model | text-embedding-3-small |
| Answer model | gpt-4.1-mini |
I deliberately limited the index to the last six months. This makes answers more relevant and reduces noise: fewer old topics, fewer conflicting formulations, easier to debug retrieval.
If you want to test it directly, open SVGLLM and ask about the recent interviews.
How the Index Works
After manual transcription, the real engineering part began. Scripts in scripts/svgllm normalize texts, split them into chunks, add YouTube metadata, verify timecodes, and assemble a static JSON index in src/server/svgllm/index.generated.json.
I chose a static index intentionally. Such a project doesn’t need a separate database, queue, admin panel, or complex ingestion pipeline. The corpus is small, updated manually, and the site should deploy like a regular Next.js project.
The scheme looks like this:
| Layer | What it does |
|---|---|
normalize-transcripts.mjs | cleans and normalizes manual transcripts |
fill-youtube-timecodes.mjs | restores and verifies fragment links |
build-index.mjs | calculates embeddings and builds JSON |
validate-index.mjs | prevents building the project with a broken index |
retrieval.ts | searches for relevant chunks and reranks results |
prompt.ts | limits the model to short answers and evidence-first logic |
This is not a “big RAG platform.” It’s a neat local system where every layer can be opened, read, and checked.
Retrieval: Why Similarity Search Alone Is Not Enough
The first working version looked plausible but quickly revealed a problem: embeddings capture meaning well but sometimes poorly handle short entity queries. The question “What is Higgsfield?” might pull chunks about AI startups in general because they are thematically close. For a human, this is obviously the wrong source, but for retrieval — “almost similar.”
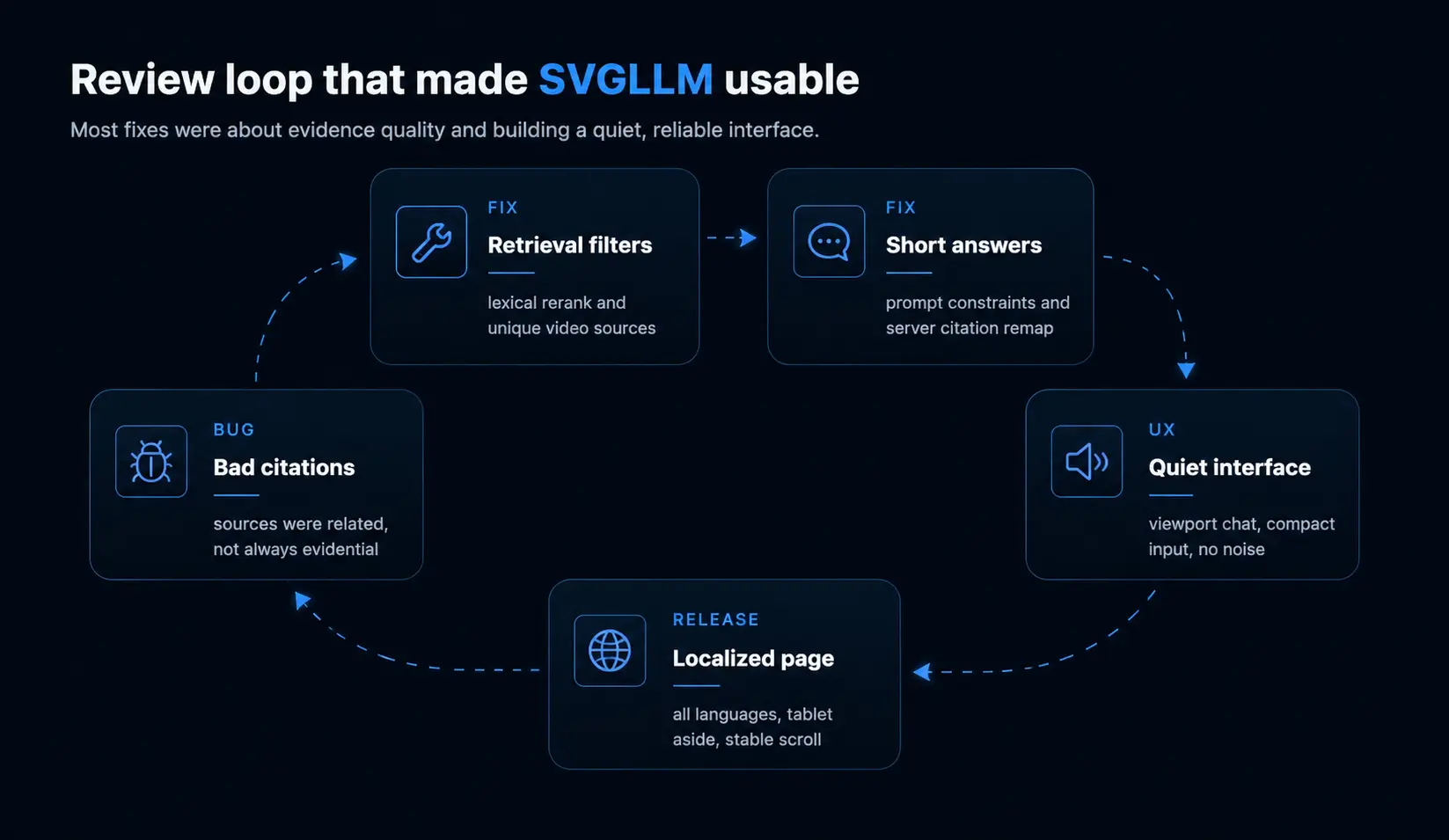
Therefore, lexical reranking was added on top of embedding similarity. If the user asks about a specific product, person, or company, matching by name should weigh more. This is especially important for queries like Higgsfield, OpusClip, Claude, Sam Altman, or specific professions.
Citation handling had to be fixed separately. The model should not decide which sources to show. The server returns only sources from retrieval results and remaps citations so that [1] in the text really corresponds to the first source card. After this, sources became part of the backend contract, not just a decorative UI block.
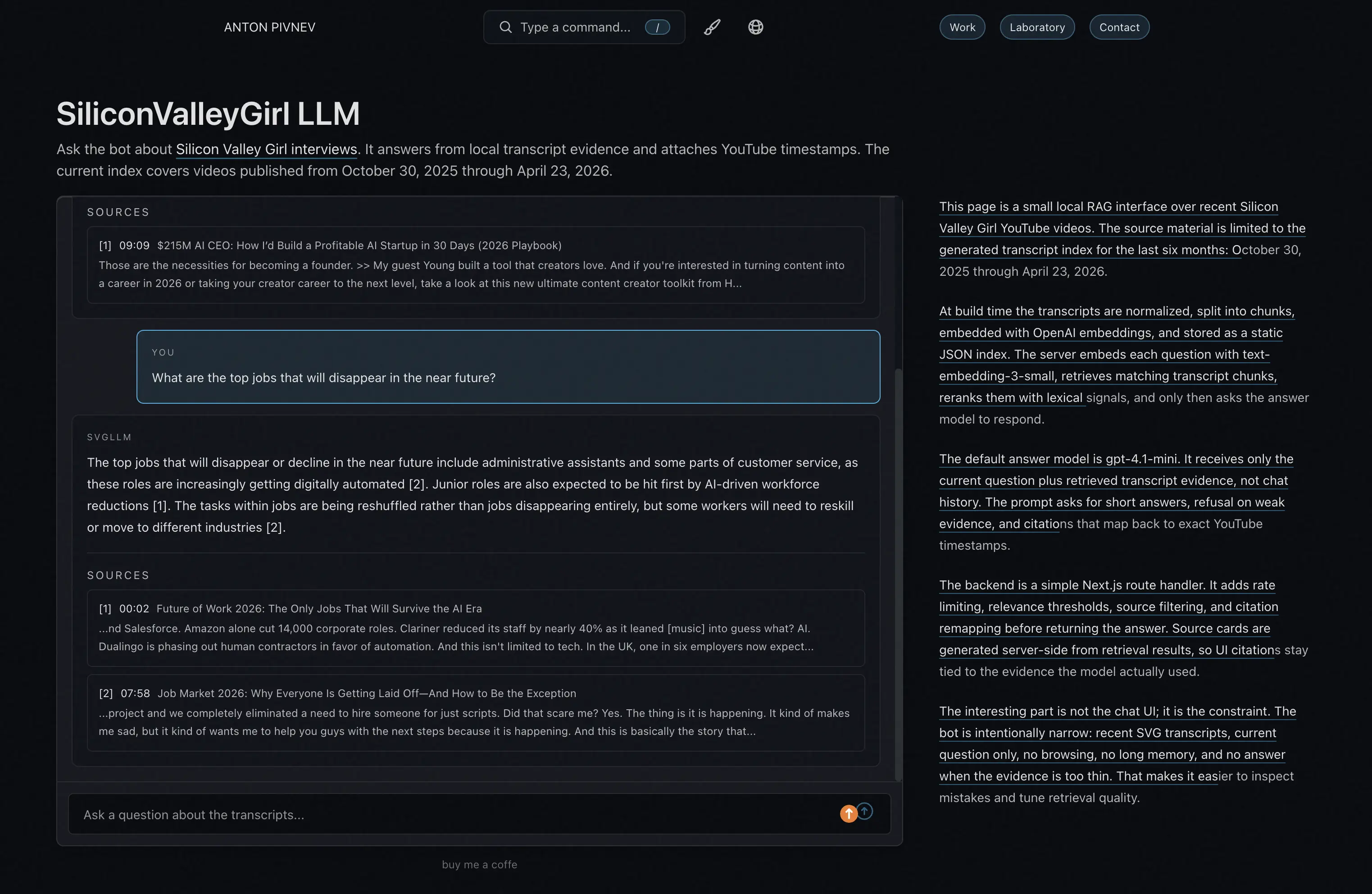
The fastest way to feel the difference is to ask the bot yourself and inspect the sources.
Prompt: Short, Only from the Corpus, No Memory
In this project, I deliberately do not send chat history. Each question is a separate request: current user input plus found transcript fragments. This makes behavior more predictable. The bot does not try to “remember context,” does not pick up past mistakes, and does not start building long reasoning on a weak base.
The prompt asks the model to:
- answer briefly;
- use only the provided transcript chunks;
- not add facts from external knowledge;
- refuse when evidence is weak;
- place citations only where there is a source;
- avoid stacking multiple footnotes unnecessarily.
It sounds simple, but these restrictions are exactly what make a small RAG useful. Here quality is not about the model saying more. Quality is about it saying less, but verifiably.
The Most Annoying Bugs Were Not in the UI
On the surface, it seemed the main work was the /svgllm page. In reality, the worst errors were at the junction of retrieval, prompt, and source rendering.
The first symptom: the bot gave overly long answers. To the question “What is Higgsfield?” it went into a detailed retelling of several tools, added unnecessary details, and attached sources that were thematically close but did not prove the specific answer.
The second symptom: two footnotes in a row like [1][2]. Formally it looks “more reliable,” but the UX is bad: the user sees noise instead of a confident link. Even worse when both footnotes point to the same video. Then the source does not strengthen the answer but just duplicates the same support.
The third symptom: with weak evidence, the bot simply said there was no confirmation. This is honest but a dead end. So the refusal was supplemented with three clickable questions that definitely have answers in the corpus. The user does not hit a wall but gets the next move.
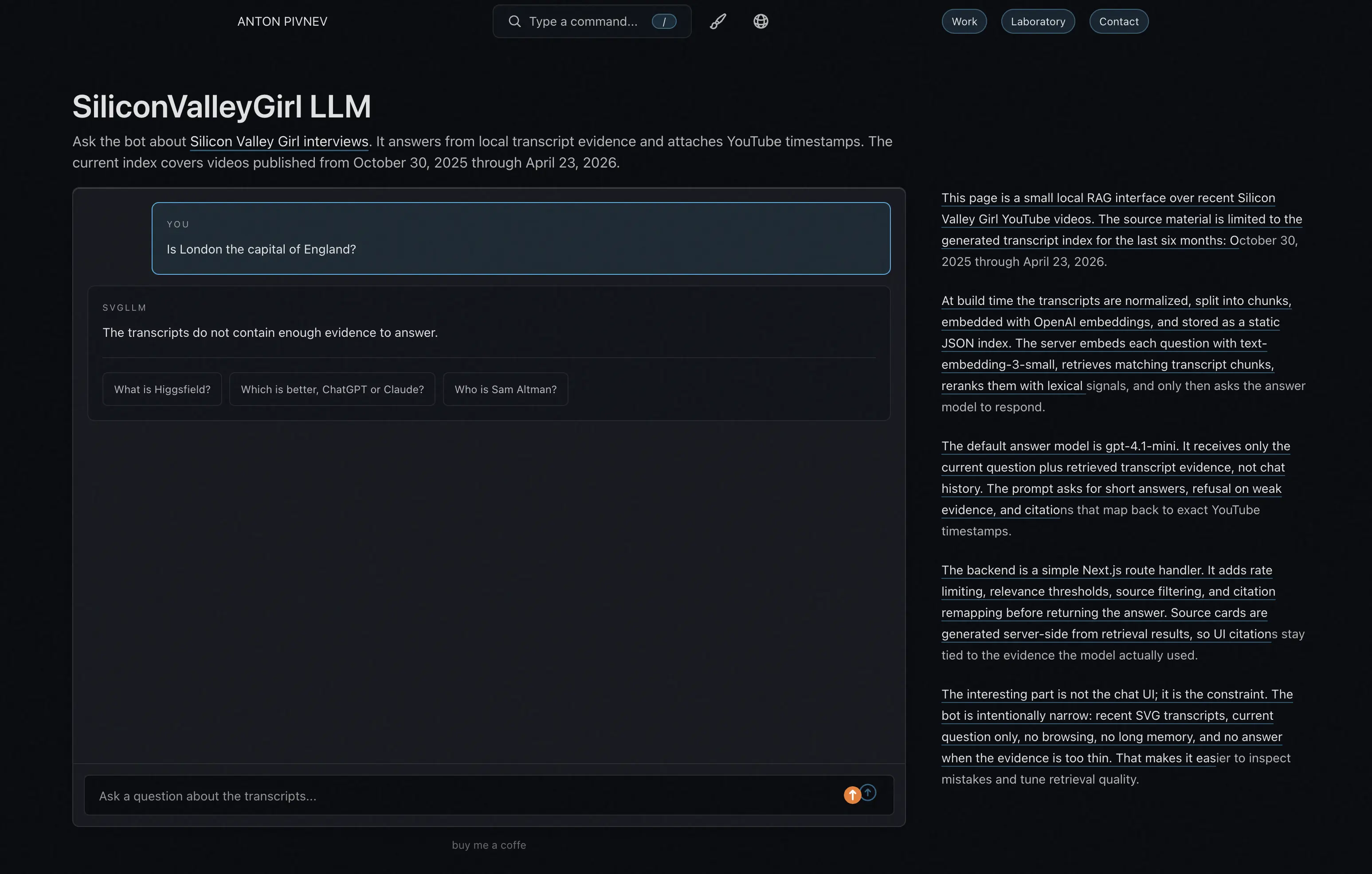
UI: Make the Chat Narrow but Not Toyish
The interface had to be rebuilt several times. At first, the page looked too demonstrative: chips, query rules, captions, extra panels. Then it became clear this is not API documentation but a working tool. All the extras went away.
The final form is:
- title
SiliconValleyGirl LLM; - link to the Silicon Valley Girl channel;
- short description with the index date range;
- large chat block with internal scroll;
- compact one-line input that grows up to three lines;
- send on
Enter, new line onShift+Enter; - icon button from Heroicons;
- unobtrusive
buy me a coffeelink with modal; - technical text on the right on desktop and tablet.
The main UX detail — the page should not jump. If there are no messages, there is an empty state. If there are many messages, the internal chat scrolls, not the whole page. After a new question, the chat scrolls so both the user’s question and the bot’s answer fit.
Why the Technical Text Is Placed Beside
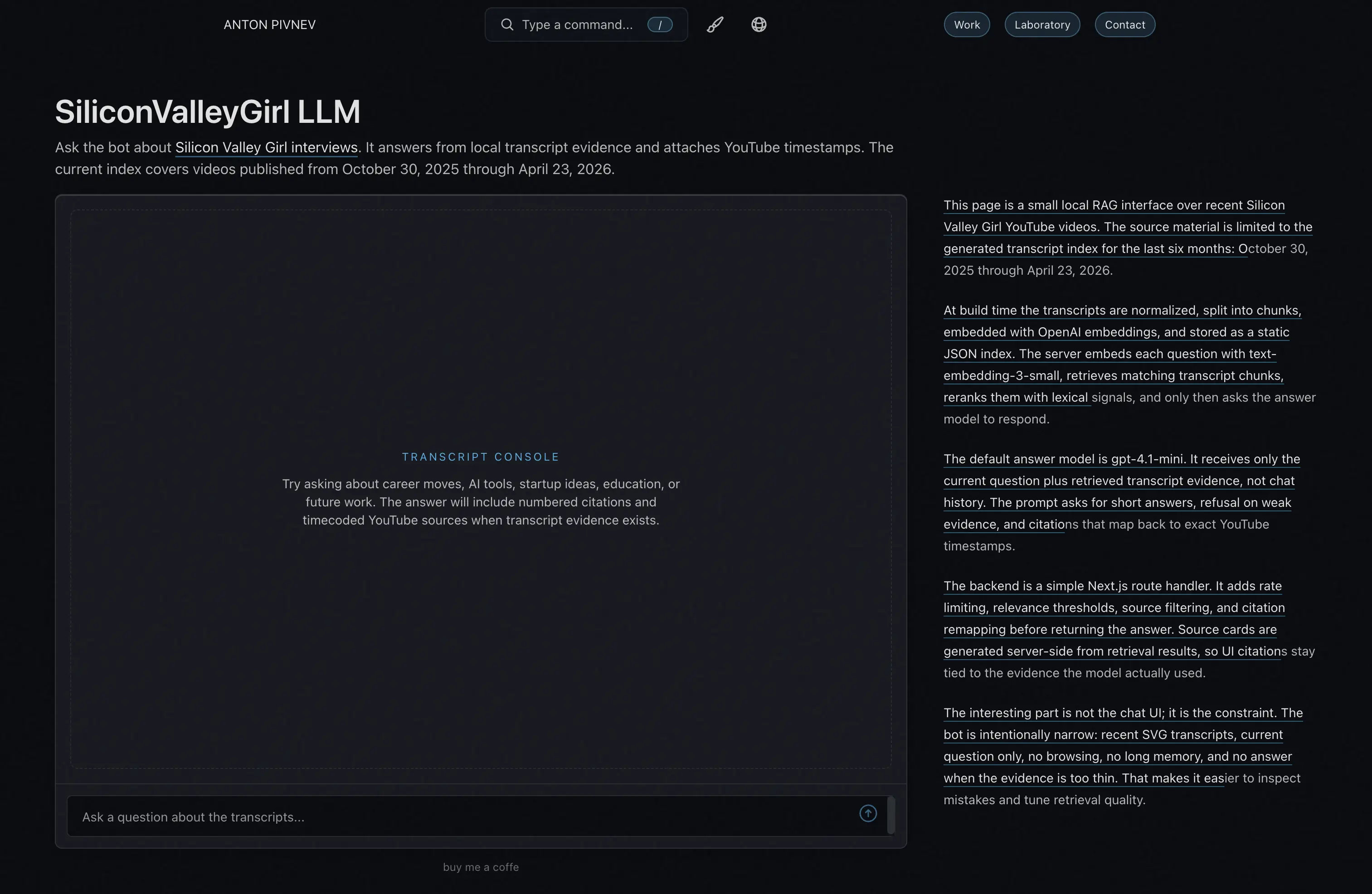
I didn’t want to turn the page into a landing. But without explanation, RAG also looks like magic. So a calm technical block appeared on the right without backgrounds or illustrations: that the index is static, that OpenAI embeddings are used, that the answer model receives only the current question and found chunks, that the backend is a regular Next.js route handler.
There are many links not for SEO but so a person can quickly understand what bricks the project is built from: RAG, embeddings, Next.js, Heroicons, Glasp, YouTube timecodes.
On tablets, this text should also be visible. This is important: it is there that it becomes clear the page is not just a “chat,” but a small experiment with a limited corpus and verifiable sources.
What Came Out in the End
It turned out not to be an “everything assistant” but a narrow tool for one set of materials. It does not browse the internet, does not remember history, does not build confident answers out of thin air, and does not try to be smarter than the corpus.
For me, this is the main conclusion of the project: a good RAG starts not with the model but with boundaries. When boundaries are clear, it’s easier to fix retrieval, easier to check citations, easier to write prompts, easier to design UI. And most importantly — easier to understand where the system really knows the answer and where it just talks nicely.
Technically, the project remained small: static index, route handler, several server modules, and a React page. From a product perspective, it became a full-fledged site page: localized, adaptive, verifiable, and honest enough not to pretend to be a universal intelligence.